
Introduction
On a phone call, speed is not a vanity metric. It is the difference between a conversation that feels human and one that feels like waiting for a machine. The architecture under the hood, speech-to-speech or cascaded, sets that ceiling before you tune anything else. This guide explains how each works, why latency stacks the way it does, and how to choose the right one for your use case.
How cascaded voice AI works
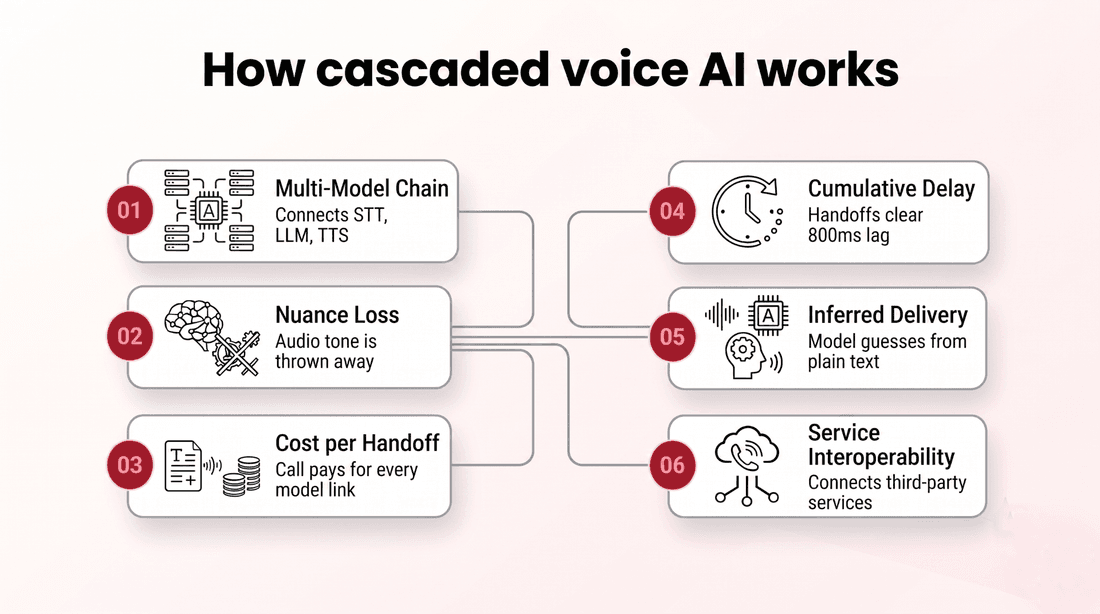
The cascaded approach, sometimes called STT, LLM, TTS, chains three separate models. First speech-to-text transcribes what the caller said. Then a language model reads that text and decides on a reply. Then text-to-speech turns the reply back into audio. Each model can be excellent on its own, yet they run in series, and the call pays for every handoff between them.
Public benchmarks put the stages in rough terms: speech-to-text near 350 ms, the language model near 375 ms, and text-to-speech near 100 ms, plus media edge, buffering, and short service hops between each. Add them and total response time often clears 800 ms before the caller hears a word. That is well past the point where a person notices the lag.
The delay is only half the cost. Every time audio is flattened into text, nuance is thrown away. The transcript of "no, that is fine" reads the same whether the caller was relieved or quietly furious, because tone does not survive the trip to plain text. The language model then reasons over words alone, and the text-to-speech stage guesses at delivery from scratch. Errors compound, too: a transcription mistake early in the chain becomes a confident wrong answer later, since each stage trusts the output of the one before it. None of this means cascaded systems are bad. It means the architecture spends effort rebuilding, imperfectly, the very signals that were present in the original audio.
How speech-to-speech works
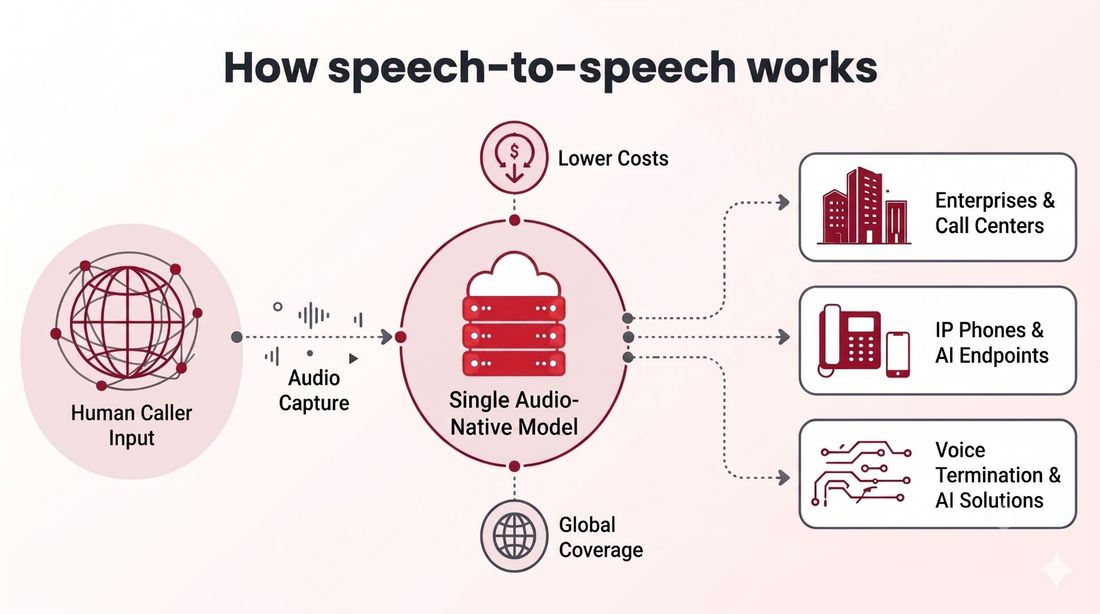
Speech-to-speech, also called audio-native or voice to voice, collapses that chain into one model. It hears audio and produces audio directly, with no text intermediary. By skipping the transcription and synthesis stages and the hops between them, it removes the largest sources of delay. Streaming audio-native systems can keep response times below the 200 to 300 ms threshold where delay becomes perceptible.
Reported results favor the shorter path: removing the separate speech-to-text and text-to-speech stages can cut latency by a large margin versus a non-streaming cascaded pipeline. Fewer stages, fewer milliseconds.
There is a second benefit beyond speed. When audio is flattened to plain text, tone, pauses, and emotion fall out. An audio-native model keeps them, so it can hear the caller's intonation and shape its own reply with matching warmth and timing. This is the design 9278.ai runs on: a single audio-native engine instead of a brittle transcribe-then-speak relay, which is what lets callers hear pauses and emotion that feel right.
Interruptions are where the difference becomes obvious. On a real call, people talk over each other constantly. They cut in to correct a detail, to say "actually, wait," or to answer before the agent finishes. A cascaded pipeline struggles here, because an interruption means tearing down a half-finished transcribe-reason-speak cycle and starting again, which produces the awkward stammer everyone recognizes as a bot. An audio-native model that streams can stop the instant it hears the caller, listen, and respond in stride, the way a person naturally yields the floor. That single behavior, smooth barge-in, does more to make a call feel human than almost anything else, and it is far easier to achieve when there is one model in the loop rather than three.
Latency, side by side
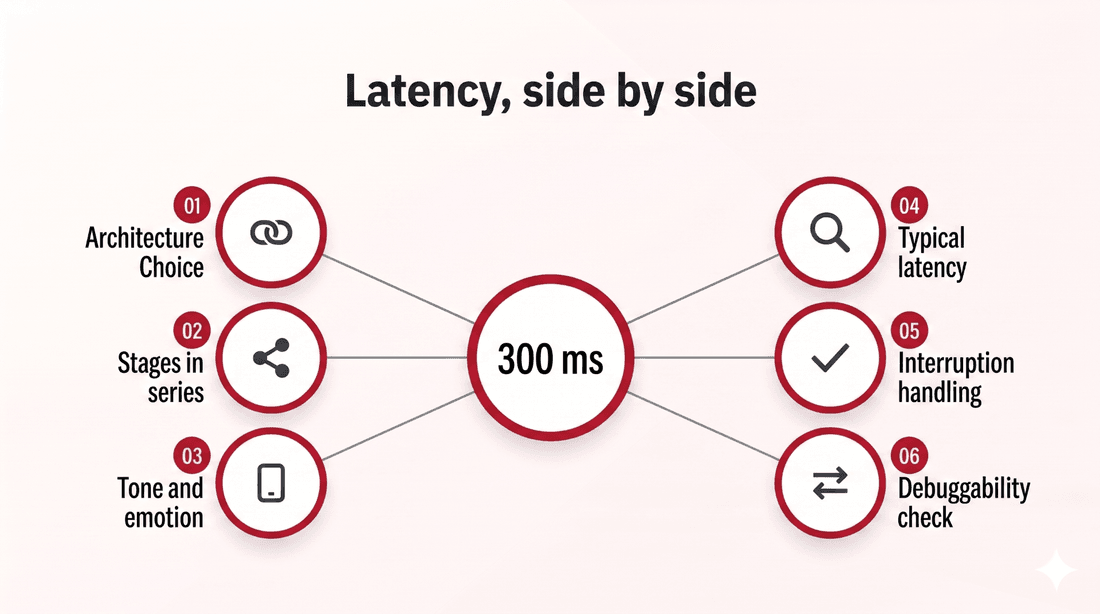
The clearest way to compare is to line the two paths up against the things callers actually feel.
| Dimension | Cascaded (STT, LLM, TTS) | Speech-to-speech |
|---|---|---|
| Typical latency | Often 800 ms or more | Can stay under 300 ms |
| Stages in series | Three models plus hops | One audio-native model |
| Tone and emotion | Lost in the text step | Preserved end to end |
| Interruptions | Harder, pipeline must reset | Natural barge-in |
| Debuggability | Per-stage visibility | Fewer seams to inspect |
Sub-second latency is the headline number to watch. A reply that lands inside 300 ms feels like a person; one that lands at 800 ms feels like dead air, and callers start talking over it.
It is worth understanding why that threshold is so unforgiving. In natural human conversation, the gap between turns is astonishingly small, often around 200 ms, and we are exquisitely tuned to it. A pause longer than that reads as hesitation, confusion, or distraction, the same way it would from a person. So when an agent consistently takes most of a second to respond, callers do not consciously think "high latency"; they think the line is laggy, or that the agent did not understand, and they repeat themselves or interrupt. That repetition then collides with a pipeline still finishing its previous turn, and the call degrades into the stop-start rhythm that screams automation. The architecture decision, made long before any prompt tuning, is what sets the ceiling on how natural that rhythm can ever feel.
When cascaded still makes sense

Speed is not the only thing teams optimize for. Cascaded pipelines dominate some enterprise deployments for reasons worth respecting.
Per-stage visibility
You can inspect the transcript, the model decision, and the audio separately, which simplifies audits.
Provider flexibility
Mix and match many speech and language vendors rather than a short list of audio-native options.
Mature tooling
Fallbacks, logging, and guardrails are well trodden across the cascaded stack.
Debugging control
When something goes wrong, you can localize it to one stage instead of one fused model.
If your priority is forensic control at every step and you can tolerate higher latency, cascaded earns its place. For most customer-facing calls, where the call has to feel human, the latency cost is the deciding factor and audio-native wins.
A simple way to decide is to name the stakes of the conversation. Internal tooling, batch QA, or a workflow where a half-second delay costs nothing can lean cascaded and enjoy the visibility. A sales line, a receptionist, a support number, or any call where a hesitation makes the caller doubt they are being heard should lean audio-native. It is also worth noting that the two are not always mutually exclusive in a stack: some teams run audio-native for the live conversation and still log full transcripts for analytics and compliance afterward, which captures much of the auditability without paying the latency tax during the call itself. Pick the property your callers will feel, then let that, not the spec sheet, settle the architecture.
Conclusion
Speech-to-speech and cascaded voice AI are not just implementation details, they set the experience. Cascaded gives you visibility and provider choice at the cost of stacked latency. Speech-to-speech trades some of that granularity for speed and preserved emotion, which is what makes a call sound human. Decide which property your callers will feel most, then pick the architecture that protects it.
Frequently asked questions
What is the difference between speech-to-speech and cascaded voice AI?
Cascaded voice AI chains three models: speech-to-text, then a language model, then text-to-speech. Speech-to-speech uses a single audio-native model that hears audio and speaks audio directly, with no text step in the middle, which removes several handoffs and cuts latency.
Why does latency matter on a voice call?
Humans notice delay past roughly 200 to 300 milliseconds. Beyond that, replies feel laggy and callers start talking over the agent. Lower latency keeps turn-taking natural, so the conversation feels like a person rather than a machine waiting for a pipeline to catch up.
Is speech-to-speech always faster than cascaded?
Usually, yes. Speech-to-speech skips the speech-to-text and text-to-speech stages and the service hops between them, which can cut total response time substantially. Cascaded pipelines add each stage in series, so latency stacks even when each model is fast on its own.
When is cascaded voice AI still the better choice?
Cascaded pipelines give you per-stage visibility, easier debugging, and a wide choice of speech and language providers. Teams with strict audit or provider-flexibility needs sometimes prefer that control, accepting higher latency in exchange for transparency at each step.
Does speech-to-speech preserve tone and emotion?
Yes. Because audio is never flattened into plain text, a speech-to-speech model can read the caller's intonation and pacing and shape its own reply to match. That is why audio-native calls carry warmth and timing that a transcribe-then-speak pipeline tends to lose.
Want to see it in action? Build your first agent or talk to the team.